Getting Started with Crawl
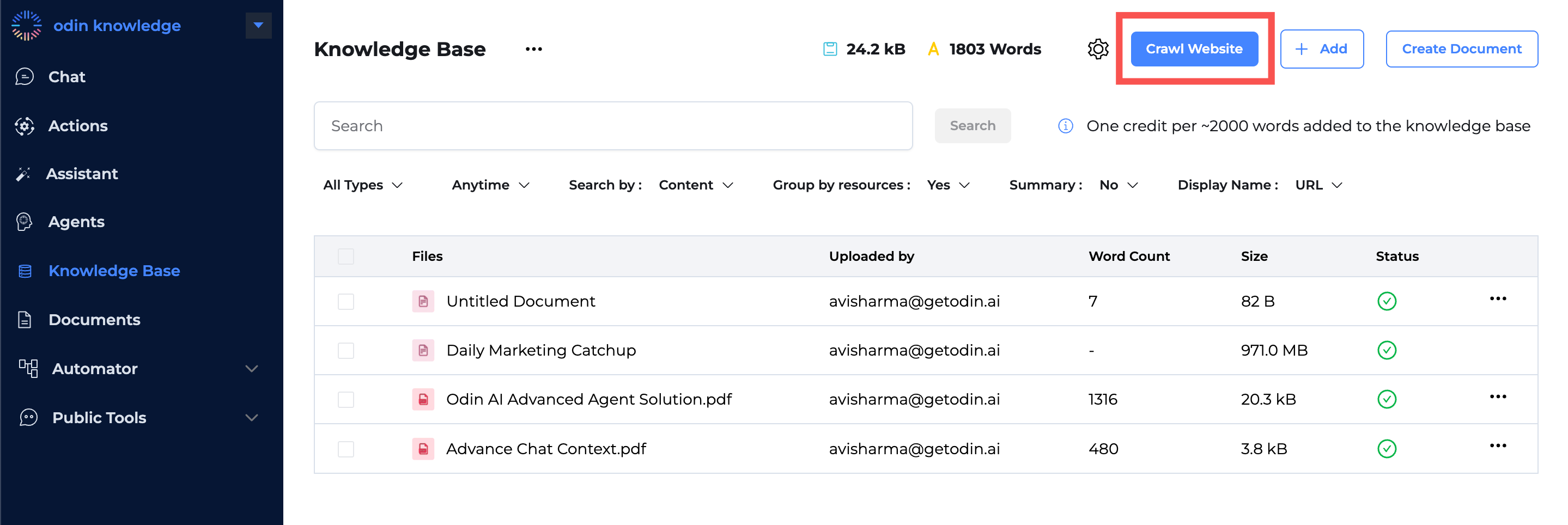
How to Find Crawler in Odin?
Sign in to your Odin account and create a project.
Open the project and click the ‘Knowledge Base’ under the left menu.
Click the ‘Crawl Website’ button on the top.
Click on the ‘+ Create New’ button to start.
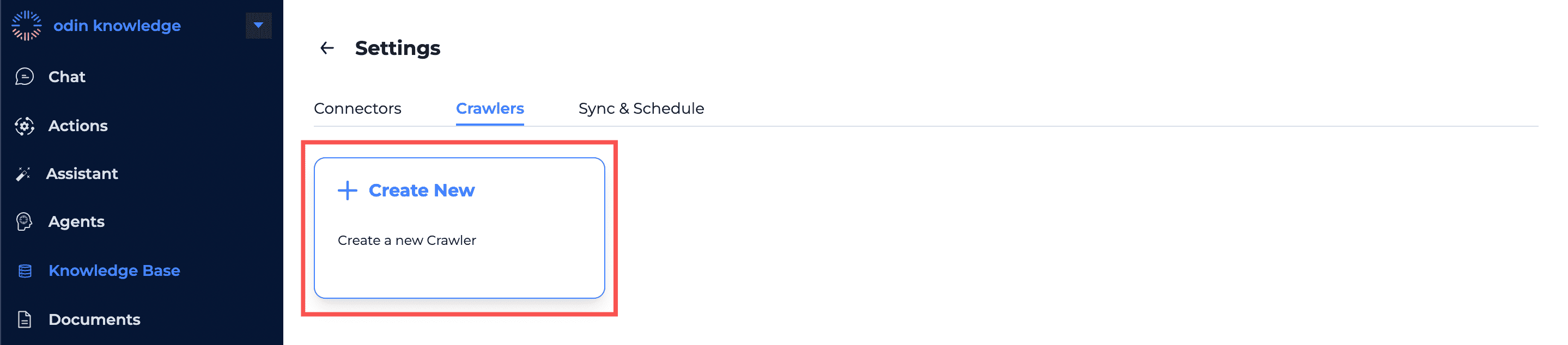
Using Crawl in the Dashboard
Utilizing Crawl involves providing a seed URL as the primary input:
- A Seed URL
For instance, initiating a crawl job with a seed URL of https://www.example.com starts the exploration of every URL within the specified domain. Subsequently, these URLs are processed accordingly.
Advanced crawl configurations incorporate additional filtering mechanisms aimed at optimizing speed and minimizing extraneous data. Customization options allow the extraction of specific content from a website.
Through advanced functionalities, crawl jobs can execute technically sophisticated tasks such as inspecting particular elements or identifying patterns within the crawled content.